Hello everyone,
It’s been a while since I have made a post here! This is mostly because I recently started working for GoodAI, an AI company that focuses on AGI research. I was kindly given permission to post about some of the stuff I have been working on here!
So, here is the latest!
HTSL2
The original HTSL was a MPF (memory prediction framework) that used very simple learning rules and architecture to understand its environment. I re-implemented it into GoodAI’s Brain Simulator, a handy tool for running CUDA-based AI simulations with reusable nodes.
The original HTSL was quite limited in that the predictions did not really affect the feature extraction process. So, it tried to “compress” everything as opposed to giving more attention to things that improve predictions. HTSL2 fixes this. In additional, it adds traces that help propagate credit for predictions back in time (as well as rewards when used with reinforcement learning).
Aside from some simple tests like the T-maze and character prediction, one of the more interesting things I was able to do was to take music and store it entirely in the working memory of HTSL2. This doesn’t show much generalization (only when it runs off of its own messy predictions), but it memorizes it quite well. We compared it to LSTM superficially on the same task, but HTSL2 gave better results (a clearer sounding audio that doesn’t decay into noise). To be fair though, HTSL2’s strength is scalability, and the audio task (I used 44100 samples/second) is relatively large. Below is some example music, the original (I don’t own it – it’s from Kevin Macleod) followed by the memorized version’s reconstruction.
Another interesting test is that of having HTSL2 learn to perform simple mathematical operations based on images of numbers. The predictions are still a bit messy right now, but it seems to work at all 🙂 . Below is an image of HTSL2 performing addition (left two digits are the first number, second two digits are the second number, and the last two digits are the result).
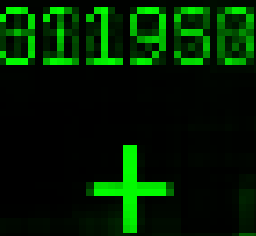
31 + 19 = 50!
Evolving a better MPF
MPFs are basically “environment understanders”, which can be used as a world model for reinforcement learning (model-based). They are a theory of how the neocortex operates. Nobody has created a MPF sufficient for AGI thus far. HTSL2 is just a starting point, which will hopefully develop into something truly useful eventually.
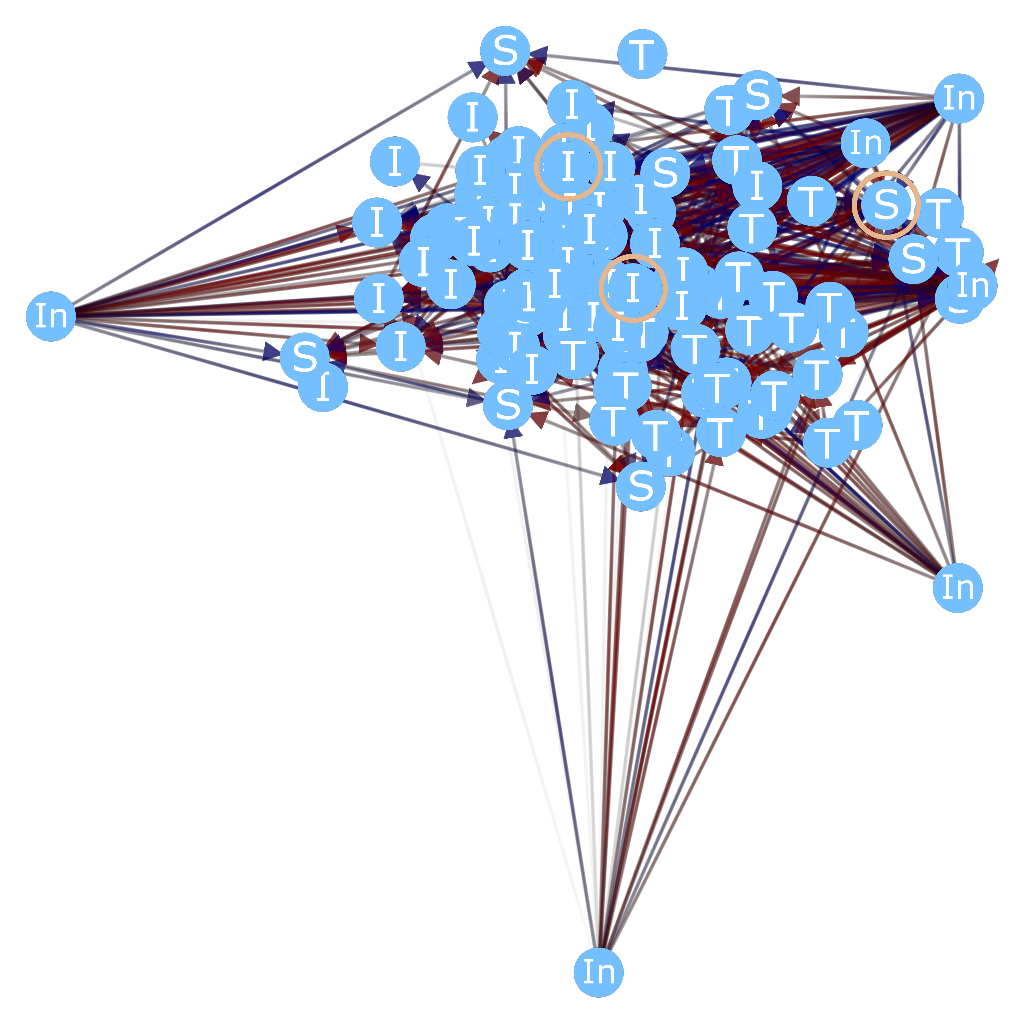
What if we could have something that designs a MPF for us? One direction of research I have been looking into is that of using genetic algorithms to create a MPF. So, I created an architecture that is generic except that it must use layers of nodes (“columns”). Everything else, the learning rules and firing dynamics included, is evolved. Right now, I have not gotten it to produce the holy grail of MPFs 😉 . I have only run it up to around generation 200 (several hours), due to lack of processing power. We are looking into ways of parallelizing the search to improve performance. It only needs to find the solution once!
Below is an image of the node (column) controller of one particular run. I made this visualizer to help us figure out why it works (when it does).
An idea for MPF-based “Human-Like” reinforcement learning
Say we have the perfect MPF, and can get perfect environmental predictions. How to use this for reinforcement learning?
I recently came up with what I believe to be a realistic explanation of what might be going on in the human brain. It accounts for Pavlovian conditioning experimental results, such as perceiving reward despite not receiving actual reward due to conditioning.
Say we predict the reward, and the action, along with the state. There are 2 kinds of rewards: external (from some sort of reward interpreter or environment), and internal. The final reward used to update the MPF predictions is then some combination of these two, where the internal reward is weaker (multiplied by some sort of decay factor).
So what is the internal reward? As the name suggests, it is generated internally by the system itself. Say that instead of just predicting the next input with our MPF, we leak in some of our own predictions. This causes a “train of thought”, which I have been able to produce in other experiments as well. Now, we can assign an internal reward for predicted rewards as well: When the agent thinks it is going to get a reward, reward the MPF, even if no external reward is present. This internal reward must be weaker than the external reward such that real rewards always have priority.
The end result is that the agent can think ahead of time what to do in order to maximize reward. This “thinking” is spread out over multiple timesteps as predictions leak in to the input.
I am currently trying to implement this idea with HTSL2. I hope that HTSL2 is good enough for this task. I am excited to see if it works like I think it should!
That’s it for now! Until next time!
