Hello again!
It’s been a couple of days, so I would like to show what I have been working on.
I now have image-to-features system, one fully functional and another that was functional but is receiving an overhaul. The former is an implementation of HTM’s spatial pooling in OpenCL. Unlike the CPU version though, this version works with continuous values. It forms sparse distributed representations of the input, but leaves out the temporal pooling portion of the fully HTM algorithm. The temporal pooling is significantly more complicated than the spatial pooling and not nearly as GPU-friendly, so I decided to just do spatial pooling for now and let the reinforcement learner take care of partial observability.
The second system is a convolutional stacked autoencoder. It runs online, and was rather difficult to parallelize due to the need for a summation of all of the gradients for each position of the filter in the receptive field. To parallelize the summation, I made a large reusable buffer that stores all the gradient values for all the convolution positions, and then did an additive downsampling. This adds 4 sub-gradients at a time (a 2×2 square) in parallel. I originally had max-pooling, but since I do not want translational invariance I removed it again.
Here is an example of a set of unique features derived from a screen of “space invaders” using the GPU-HTM:

Here is an example of the convolutional autoencoder (GPU-CAE) representing the number 2:
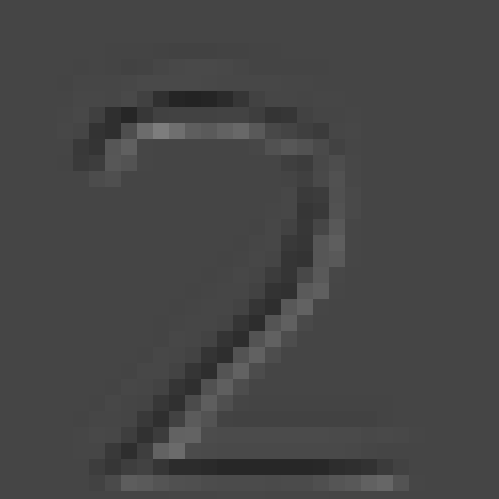
The code is not part of the main repository yet, but I will soon upload the modified ALE along with the new code.
That’s it for this update!
See you next time!
